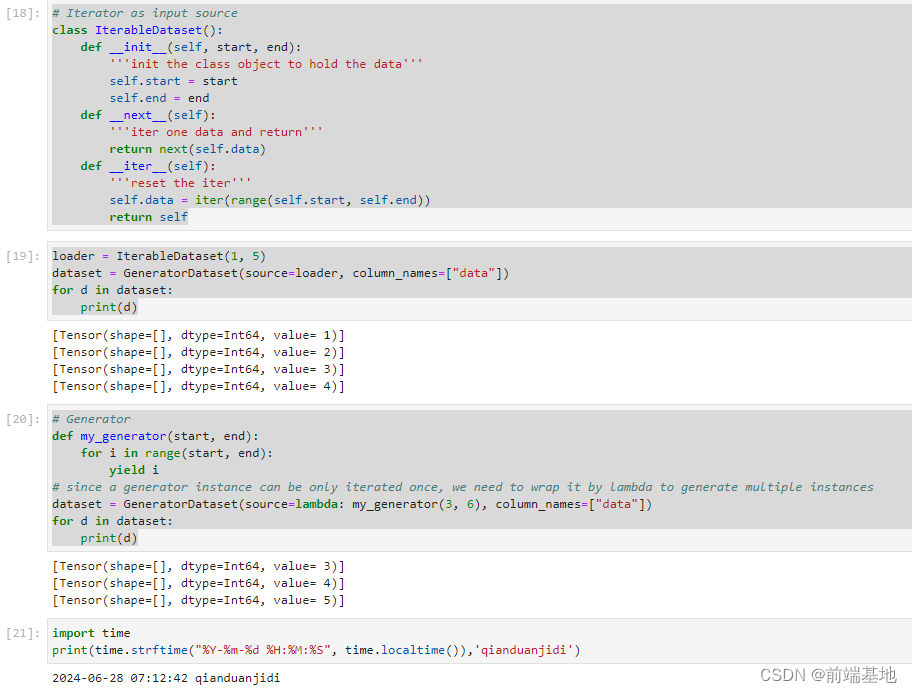
python默认编码
python 2.x默认的字符编码是ASCII,默认的文件编码也是ASCII。
python 3.x默认的字符编码是unicode,默认的文件编码是utf-8。
中文乱码问题
无论以什么编码在内存里显示字符,存到硬盘上都是二进制,所以编码不对,程序就会出错。
常见编码有ascii编码(美国),GBK编码(中国),shift_JIS编码(日本),unicode(统一编码)等。
需要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就会出现乱码问题。
常见的编码错误的原因有如下,出现乱码时,按照编码之前的关系,挨个排错就能解决问题。
python解释器的默认编码;
Terminal使用的编码;
python源文件文件编码;
操作系统的语言设置。
Python支持中文的编码:utf-8、gbk和gb2312。uft-8为国际通用,常用有数据库、编写代码。gbk如windows的cmd使用。
编码转换
如果想要中国的软件可以正常的在美国人的电脑上实现,有下面两种方法:
让美国人的电脑都装上gbk编码
让你的软件编码以utf-8编码
第一种方法不可现实,第二种方法比较简单,但是也只能针对新开发的软件,如果之前开发的软件就是以gbk的编码写的,上百万行代码已经写出去了,重新编码成utf-8格式也会费很大力气。
所以,针对已经用gbk开发的软件项目如何进行编码转换,利用unicode的一个包含了跟全球所有国家编码映射关系的功能,就可以实现编码转换。无论以什么编码存储的数据,只要我们的软件把数据从硬盘上读到内存,转成unicode来显示即可,由于所有的系统、编程语言都默认支持unicode,所有我们的gbk编码软件放在美国电脑上,加载到内存里面,变成了unicode,中文就可正常展示。
类似用如下的转码的过程:
源有编码 -> unicode编码 -> 目的编码
decode(“UTF-8”) 解码 --> unicode --> encode(“gbk”) 编码
coding:utf-8 的作用
在python2文件中,经常在文件开头看到“ #_coding:utf-8 _ ”语句,它的作用是告诉python解释器此.py文件是utf-8编码,需要用utf-8的编码去读取这个.py文件。
python2.x的bytes与python3.x的bytes的区别
Python2将string处理为原生的bytes类型,而不是 unicode。而Python3所有的 string均是unicode类型。
在python2.x中,写字符串,比如
>>>s = ”学习“
>>>print s
学习
>>>s # 字节类型
'\xd1\xa7\xcf\xb0'
虽然说打印的是中文学习,但是直接调用变量s时,显示的却是一个个16进制表示的二进制字节,我们称这个为byte类型,即字节类型,它把8个二进制组成一个byte,用16进制表示。
所以说python2.x的字符串其实更应该称为字符串,通过存储的方式就能看出来,但是在python2.x中还有一个bytes类型,两个是否相同呢,回答是肯定的,在python2.x中,bytes==str。
python3.x中,把字符串变成了unicode,文件默认编码为utf-8。这意味着,只要用python3.x,无论我们的程序以那种语言开发,都可以在全球各国电脑上正常显示。
python3.x除了把字符串的编码改成了unicode,还把str和bytes做了明确区分,str就是unicode格式的字符串,而bytes就是单纯的二进制。(补充一个问题,在python3.x中,只要把unicode编码,字符串就会变成了bytes格式,也不直接打印成gbk的字符,我觉得就是想通过这样的方式明确的告诉你,想在python3.x中看字符串,必须是unicode,其他编码一律是bytes格式)。
深入中文编码问题
python3内部使用的是unicode编码,而外部却要面对千奇百怪的各种编码,比如作为中国程序经常要面对的gbk,gb2312,utf8等,那这些编码是怎么转换成内部的unicode呢?
首先看一下源代码文件中使用字符串的情况。源代码文件作为文本文件就必然是以某种编码形式存储代码的,python2默认源代码文件是asci编码,python3默认源代码文件是utf-8编码。比如给python2代码文件中的一个变量赋值:
s1 = ‘a’
print s1
python2认为这个字符’a’就是一个asci编码的字符,这个文件可以正常执行,并打印出’a’字符。在仅仅使用英文字符的情况下一切正常,但是如果用了中文,比如:
s1 = ‘哈哈’
print s1
这个代码文件被执行时就会出错,就是编码出了问题。python2默认将代码文件内容当作asci编码处理,但asci编码中不存在中文,因此抛出异常。
解决问题之道就是要让python2解释器知道文件中使用的是什么编码形式,对于中文,可以用的常见编码有utf-8,gbk和gb2312等。只需在代码文件的最前端添加如下:
# -- coding: utf-8 --
这就是告知python2解释器,这个文件里的文本是用utf-8编码的。这样,python就会依照utf-8的编码形式解读其中的字符,然后转换成unicode编码内部处理使用。
不过,如果你在Windows控制台下运行此代码的话,虽然程序是执行了,但屏幕上打印出的却不是哈哈字。这是由于python2编码与控制台编码的不一致造成的。Windows下控制台中的编码使用的是gbk,而在代码中使用的utf-8,python2按照utf-8编码打印到gbk编码的控制台下自然就会不一致而不能打印出正确的汉字。
解决办法一个是将源代码的编码也改成gbk,也就是代码第一行改成:
# -- coding: gbk --
另一种方法是保持源码文件的utf-8不变,而是在’哈哈’前面加个u字,也就是:
s1=u’哈哈’
print s1
这样就可以正确打印出’哈哈’字了。这里的这个u表示将后面跟的字符串以unicode格式存储。python2会根据代码第一行标称的utf-8编码,识别代码中的汉字’哈哈’,然后转换成unicode对象。如果我们用type查看一下’哈哈’的数据类型type(‘哈哈’),会得到<type ‘str’>,而type(u’哈哈’),则会得到<type ‘unicode’>。
type(‘哈哈’)
<type ‘str’>
type(u’哈哈’)
<type ‘unicode’>
也就是在字符前面加u就表明这是一个unicode对象,这个字会以unicode格式存在于内存中,而如果不加u,表明这仅仅是一个使用某种编码的字符串,编码格式取决于python2对源码文件编码的识别,这里就是utf-8。
Python2在向控制台输出unicode对象的时候会自动根据输出环境的编码进行转换,但如果输出的不是unicode对象而是普通字符串,则会直接按照字符串的编码输出字符串,从而出现上面的现象。
使用unicode对象的话,除了这样使用u标记,还可以使用unicode类以及字符串的encode和decode方法。
unicode类的构造函数接受一个字符串参数和一个编码参数,将字符串封装为一个unicode,比如在这里,由于我们用的是utf-8编码,所以unicode中的编码参数使用’utf-8’,将字符封装为unicode对象,然后正确输出到控制台:
s1=unicode(‘哈’, ‘utf-8′)
print s1
另外,用decode函数也可以将一个普通字符串转换为unicode对象。很多人都搞不明白python2字符串的decode和encode函数都是什么意思。这里简要说明一下。
decode函数是将普通字符串按照参数中的编码格式进行解析,然后生成对应的unicode对象,比如在这里我们代码用的是utf-8,那么把一个字符串转换为unicode对象就是如下形式:
>>> s2 = '哈哈'.decode('utf-8')
>>> type(s2)
<type 'unicode'>
这时,s2就是一个存储了’哈哈’字符串的unicode对象,其实就和unicode(‘哈哈’, ‘utf-8′)以及u’哈哈’是相同的。
encode函数正好就是相反的功能,是将一个unicode对象转换为参数中编码格式的普通字符串,比如下面代码:
>>> s3 = unicode('哈哈', 'utf-8').encode('utf-8')
>>> type(s3)
<type 'str'>
或者:
>>> s3 = '哈哈'.decode('utf-8').encode('utf-8')
>>> type(s3)
<type 'str'>
s3现在又变回了utf-8的’哈哈’。同样的,也可指定其它编码格式,但要注意的是,用什么格式编码,就用什么格式解码,否则会出现中文乱码问题。
字符编码
目前使用的编码方式有:ASCII码(一个字节)、Unicode码(两个字节)、UTF-8码(可变长的编码)。我们已经知道了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符’0’用ASCII编码是十进制的48,二进制的00110000,注意字符’0’和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
字符 ASCII Unicode UTF-8
A 01000001 00000000 01000001 01000001
中 x 01001110 00101101 11100100 10111000 10101101
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
编码方式
1.ASCII
现在我们面临了第一个问题:如何让人类语言,比如英文被计算机理解?我们以英文为例,英文中有英文字母(大小写)、标点符号、特殊符号。如果我们将这些字母与符号给予固定的编号,然后将这些编号转变为二进制,那么计算机明显就能够正确读取这些符号,同时通过这些编号,计算机也能够将二进制转化为编号对应的字符再显示给人类去阅读。由此产生了我们最熟知的ASCII码。ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。这样在大部分情况下,英文与二进制的转换就变得容易多了。
2.GB2312
虽然计算机是美国人发明的,但是全世界的人都在使用计算机。现在出现了另一个问题:如何让中文被计算机理解?这下麻烦了,中文不像拉丁语系是由固定的字母排列组成的。ASCII 码显然没办法解决这个问题,为了解决这个问题,中国国家标准总局1980年发布《信息交换用汉字编码字符集》提出了GB2312编码,用于解决汉字处理的问题。1995年又颁布了《汉字编码扩展规范》(GBK)。GBK与GB 2312—1980国家标准所对应的内码标准兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。这样我们就解决了计算机处理汉字的问题了。
3.Unicode
现在英文和中文问题被解决了,但新的问题又出现了。全球有那么多的国家不仅有英文、中文还有阿拉伯语、西班牙语、日语、韩语等等。难不成每种语言都做一种编码?基于这种情况一种新的编码诞生了:Unicode。Unicode又被称为统一码、万国码;它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode支持欧洲、非洲、中东、亚洲(包括统一标准的东亚象形汉字和韩国表音文字)。这样不管你使用的是英文或者中文,日语或者韩语,在Unicode编码中都有收录,且对应唯一的二进制编码。这样大家都开心了,只要大家都用Unicode编码,那就不存在这些转码的问题了,什么样的字符都能够解析了。
4.UTF-8
但是,由于Unicode收录了更多的字符,可想而知它的解析效率相比ASCII码和GB2312的速度要大大降低,而且由于Unicode通过增加一个高字节对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符。对可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,而对ASCII来说高字节的0毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。而我们最常用的UTF-8就是这些转换格式中的一种。在这里我们不去研究UTF-8到底是如何提高效率的,你只需要知道他们之间的关系即可。




![[游戏开发][UE5]引擎学习记录](https://img-blog.csdnimg.cn/direct/a0ee1c2ccf7349128c2c6f29f9b601f1.png)